I’ve struggled today with tracking down a weird event that results in an error that triggers 2 events.
Background: I’m sending some data to a remote API (thingsboard) that is collected around the internet. This node red instance runs in azure docker container and for some reason it will frequently fail http requests (typically with ECONNRESET or ETIMEDOUT). To mitigate this and also make it more robust in general, I have built a system around the http request node that can detect when it fails and handle it by either retry X amount of times after a defined timeout or add it to a backup queue which will resend failed requests in batches at a set interval (5 min). I’ve transitioned away from using retry attempts and instead use backup msg queue.
All of this runs smooth so even if something fails now and then, it eventually succeeds when failed messages are sent again from the backup queue. However, when this is logged, I notice it logs the error happening twice. And it logs data being sent from backup twice. Somewhere I’m getting duplicate messages from the same error! Unfortunately I haven’t found a way to trigger these errors locally, so I can only adjust logging of production instance and wait and hope for error to trigger again and see if I understand more. So far I have not ![]()
How does HTTP request node behave with these errors? Does it throw an exception? Or does it output the msg as normal and signal the error in statusCode and/or error attributes? At the moment I handle both cases separately and chatgpt suggests this as the source of duplicate error handling:
-
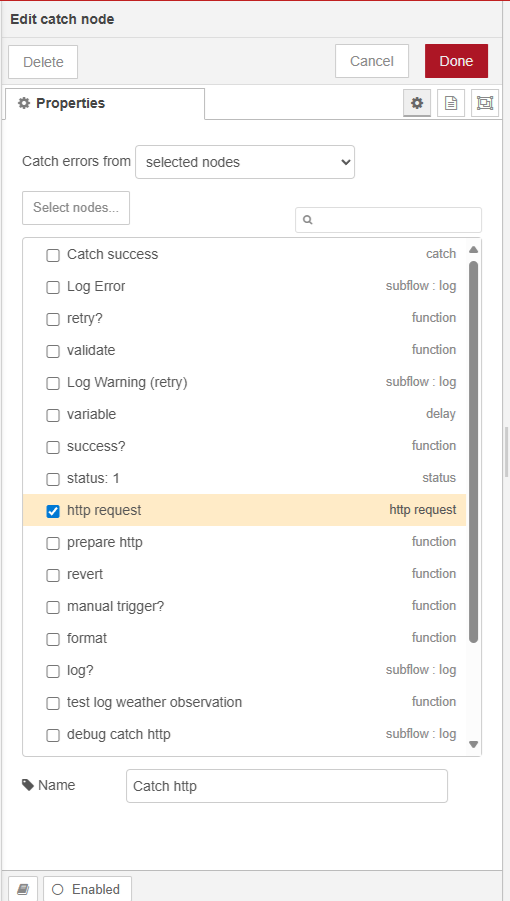
function node picks up the msg from http node and throws an error if status is not 200. This is caught by catch node A.
-
Another catch node B listens for HTTP node.
Can’t share the subflow here as it’s too large, but perhaps a screenshot can help: