I need some advice on Node-RED performance optimization. My Node-RED environment feels slow — nodes take time to open and became un reponsive for few seconds and deploying a flow takes 3–4 seconds (sometimes more).
My Questions
===========
Is there a way to check which nodes or parts of my flow are causing bottlenecks. I imagine, i might have to optimize the flow but still i have to know what is causing it and where to start
Currently below are the parts of the flow that i feel might be causing issues. Again I have no way of knowing:
Lots of float → string → float conversions happening every sec (to round of values).
Many `setInterval()` inside func nodes to generate value every seconds
Around 200-250 node/flow context set-get operations running simultaneously.
My Setup
===========
Running Node-RED on Windows (Lenovo i5-5300U, 16 GB RAM, 256 GB SSD) & Docker.
Will later deploy to Pi 4 (4 GB RAM, 64 GB storage) in production to log mc data.
I have a total of 330 nodes, 10 groups, 2 config nodes,5 mysql nodes
Generates simulated values every sec ( setInterval()) stores in context, pushes to MySQL. If any value changes, all data in a given set of variables pushed to MySQL.
set of 4 variables to sql_table1
set of 4 variables to sql_table2
set of 5 variables to sql_table3
set of 36 variables to sql_table4
set of 60 variables to sql_table5
Flow-2:
I have a total of 91 nodes, 8 groups and includes 5 mysql nodes
Subscribes to PLC data every second, stores in context, then pushes to MySQL
Same table structure as Flow 1
Any suggestion even small ones are welcome. Looking forward for your response.
Even with just a few and the output turned off, if the number of messages going through is significant, I believe this can still have an impact. Try disconnecting them from their outputs to see if that helps at all.
The real impact comes from having multiple wires coming out of a node's output port. This forces Node-RED to deep clone the msg object which is comparatively slow. So check your flow for that.
Perhaps try to limit that, you only need the rounding just before display. Depending on how you are displaying things, you might even be able to offload the rounding to clients rather than the server.
Are you using prepared statements for your pushes? If not, you should.
That is a lot of data to update at one time. prepared statements will reduce overheads a lot there I think.
Check the size of your context variables. Also, have you made those retained or just in memory?
Also check your device and make sure you aren't seeing any SWAP activity as that is a real performance killer.
Also, check your SQL tables and make sure you have sensible indexes and do the indexes all fit into memory?
From what I can make of this (without seeing flows) I suspect your approach is the problem. You may even be causing back pressure due to many 1sec timers firing)
Doing set timeout in function nodes should be avoided unless you are storing the timer handle and cancelling them upon deploy (you can easily end up with duplicates, triplicates, quad, ... firings) Just use inject nodes set to repeat instead.
Next, instead of polling everything, try to be more event based. E.g. use RBE (Aka filter node) to detect value changes and only then bother to do conversions and update context.
Also, if you are using subflows unnecessarily, they can contribute to slower deploys.
Lastly, if you are doing full deploy instead of node-change deploys, things will take longer.
System bottleneck is not the issue — I already checked. The bottleneck in my case has nothing to do with the flow being deployed. Even before and after deploying the flow, Node-RED’s UI screen is not running fluidly, mouse cursor hangs and if i remember it correctly, node red UI was always fluid. Also, issue is same on Docker as well (slightly more bad). FYI,
Before deploying the flow
mysqld.exe: 0–0.1% CPU, ~20 MB memory
node.js: 0–0.1% CPU, ~115 MB memory
Overall system: < 30% CPU, 52% memory
After deploying the flow
mysqld.exe: 0–0.1% CPU, ~23 MB memory
node.js: 0–0.1% CPU, ~125 MB memory
Overall system: < 30% CPU, 52% memory
I am pasting the GIF image. (stuttering can be seen)
Also, i removed most of the node in my flow and still my node red environment is stuttering (not fluid). I wonde if it stuttering will also affect node-red processing performance
I'm doing exactly what you assume that " incrementing counter value which runs at certain interval when BOOLEAN TRUE is the input and stops when BOOLEAN FALSE is the input".
I could have opt for multiple inject node to control the timer interval but that is the optimum approach in my case. I wanted to control all simulated values (be it may incrementor, or random, running at different intervals) with only two inject buttons (BOOLEAN TRUE AND BOOLEAN FALSE). So, i have no options other than set interval (correct me if i'm wrong)
I'm using filter node not during generating simulated values. but before pushing value to sql server. Conversion (float > string > float) is not that much resource intensive and removing it does not doing make a difference in my case (I removed the conversion as told by "@TotallyInformation " and will do it grafana).
I have no subflows in my flow
I can deal with this. But in my case node red is running fluidly and stuttering
So what is consuming 30% CPU and 50% memory? That is a lot of CPU and memory for quiescent conditions. I don't think the issue is anything to do with the node red flows. It sounds more like a browser issue.
Do you see the same if you run the browser on a different PC, connecting to node red on the 1st machine?
What browser/version are you using? Can you try a different one?
I am pasting the part of code (this will help make sense of what i'm trying to do). Let me know if you require complete flow. temp.json (88.2 KB)
Yes, i'm running node-red on docker, window, PI which is communicating with MySQL server running on same window PC.
Yeah right now, I'm doing stress test with MySQL server + PLC + PLC-PC protocols with no code breaks=> testing the data insertion limit, variables quantity, minimum interval without crashing and bottlenecking, error logging, etc... So, higher the number of variables, more better.
I feel, browser is not the issue as firefox also produced same result. (earlier i was using chrome)
However, just for curiosity, i tested things on different PC (8gb ram dual channel, 256 ssd thinkpad carbon, i5-8350 (quad core)). Here, things are lot better, though things are still not 100% smooth, but stuttering is reduced by approx 80%. This time i also ran the same flow on PI as well and access it using new PC browser, same better performance as it was running on new PC node-red.
But, it shouldn't have happened as node-red is least resouce intensive thing ideal for low-spec devices, i don't know what causing it in my case(dual core processor - i5-5300U). I shared the flow part to @jbudd reply. flow have "lot of redundencies which i'm taking care of on the go" but still removing it is not making a difference.
By stuttering I assume you mean that the mouse and node opening are not smooth, as in the gif you posted? Do you see that when looking at other sites in the browser?
Also you did not answer the question as the what processes are using the CPU and memory.
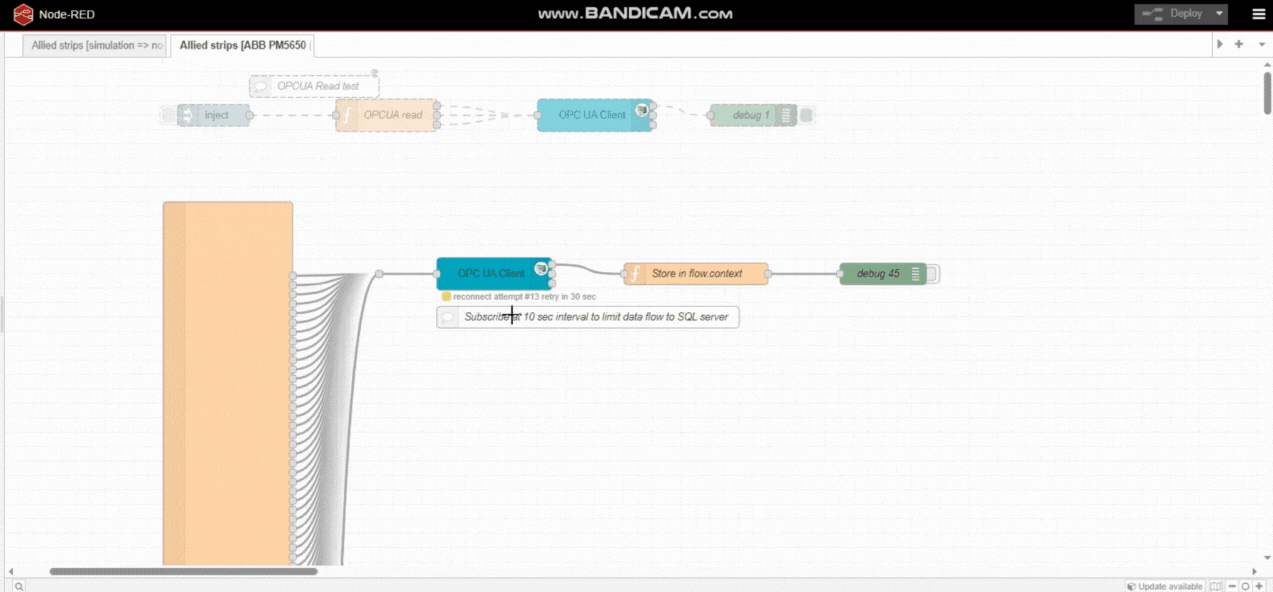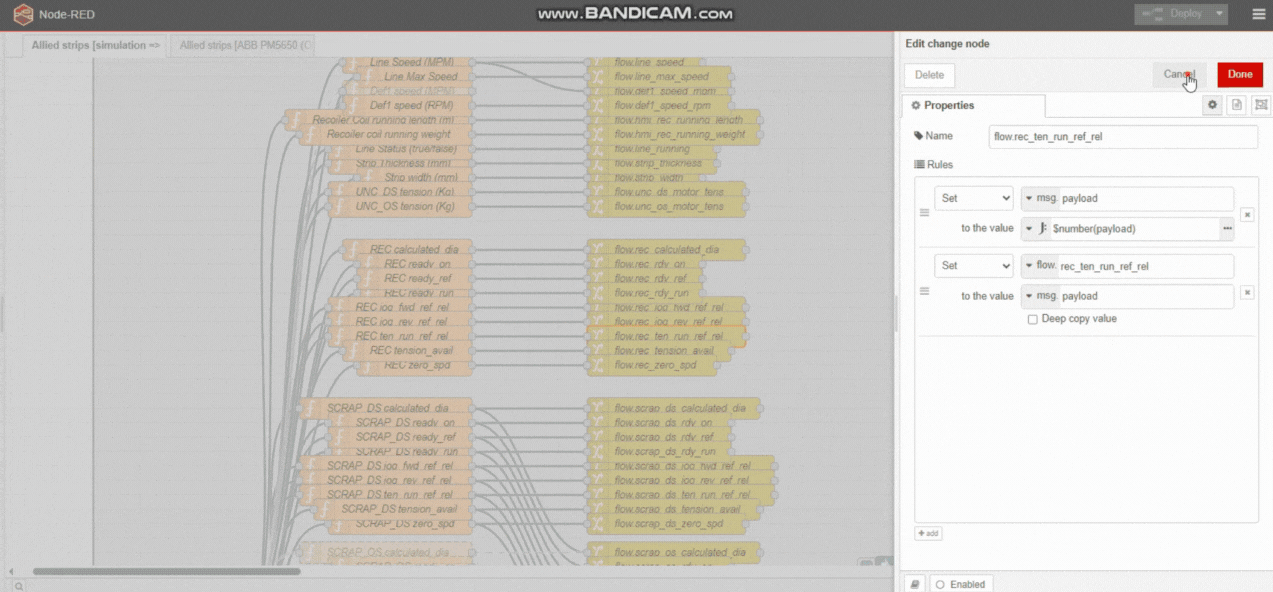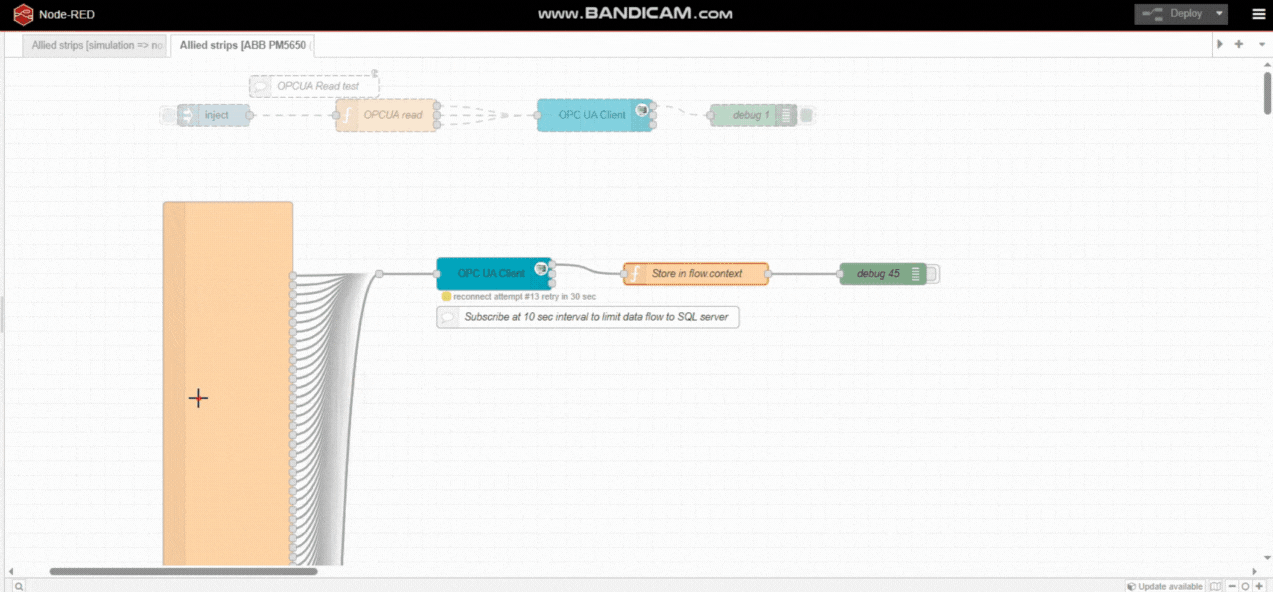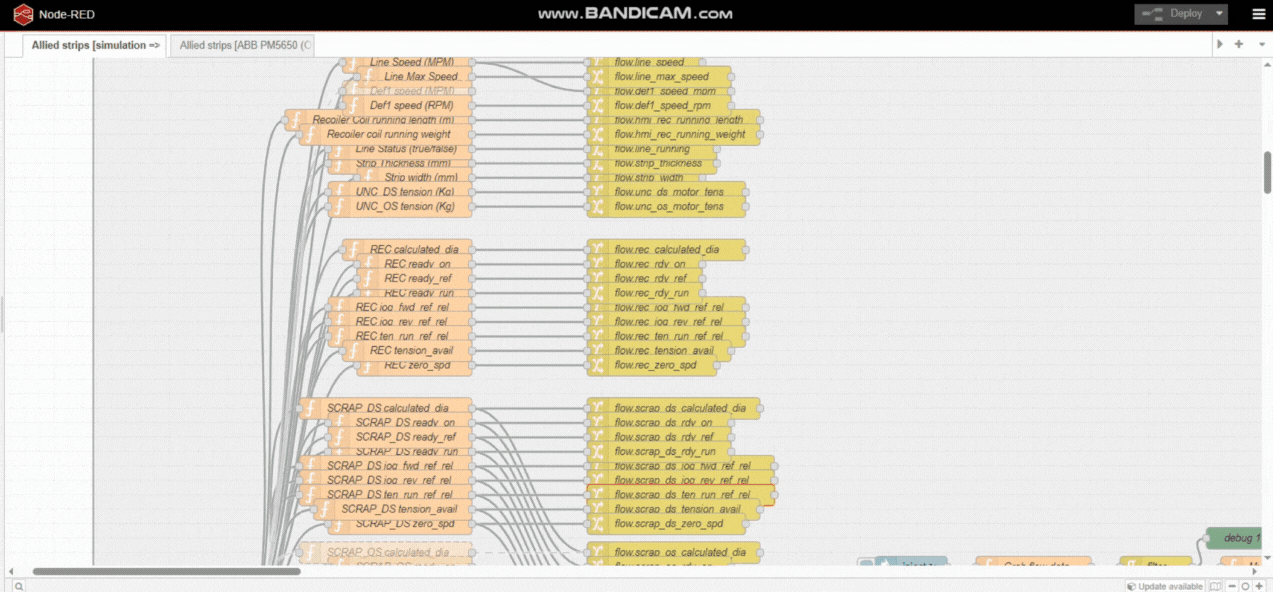
I feel sure that you could combine these 6 functions into 1.
Instead of 'isRunning' and 'Interval' context variables for each function you would need an object, possibly something like this
Indeed, by using msg.topic to identify the machine, you may get all of this into a single function and context variable.
Since you [currently] have a function node on each wire, you could dispose of the change nodes by ensuring msg.payload is numeric and setting flow variables in the function.
Your Grab Flow Data node would be greatly simplified if a single context variable held an object with all values.
Your Insert statement is insecure. You should read up on prepared statements for MySQL in Node-red
I wouldn't say other sites are fluidly smooth but i do not see stuttering while navigating other websites page or hanging of mouse cursor.
I don't remember exactly but it might be YT page or multiple tabs opened in the background. But i would say, even scrolling webpages fast including node red's increases the CPU load from 20% to 40-50% (sometimes more) instantly. [Also FOX also performing the same].
You're definitely right about it. This way a single function node when having input msg.payload=True, can start multiple timer executing at different interval and only two context storage will suffice. Also, flow context can also be included. And, instead of sending value via payload, we can directly update to flow context in the function node itself [I hope this is what you meant]
Yeah i know that insert_statement is prone to SQL injection but i would have taken care of it later. But still thanks for letting me know.
I rather doubt it.
It would never occur to me to use a function node to start a timer, nor would I know how to do it. Instinct says it's a bad idea.
Every now and then I have included a delay node in my flows to try and ensure that one external process has completed before moving on. Even so it's poor coding style.
I don't know what your True and False inject nodes represent, but I assume that's where the machine data arrives in the flow.
Other people might have a grasp of the business process you are coding, I don't so I don't think I can make any more useful comments.
To see if the node-red flows are a factor, stop node-red and start it in Safe mode (I don't know how to do that, but no doubt google will tell you). That will start the node-red editor but not the flows. See how the browser performs like that.
Starting Node-RED in safe mode doesn’t make any difference.
In my case, I’d say Node-RED definitely stutters in the browser (both Chrome and Firefox — though slightly less in Firefox). I suspect this has more to do with my work PC (i5-5300, 16 GB RAM, 256 GB SATA) rather than Node-RED itself. However, when I access the same Node-RED environment on a different PC with the same Chrome version, the stuttering is not present (only very slight delays, which are expected if the number of flows is large and each contains many nodes).
Still, I hope there would've been a way to quantify which flow(among others) is causing delays, and to understand the optimum number of nodes/code beyond which load increases and things start taking longer to load. If not, can you tell me if i can use any workaround?
If it is the browser stuttering, even when node-red isn't running, it can't be a node-red issues can it?
Having dealt with corporate IT for decades, I would certainly point at the PC itself being the issue. It is very common for the lockdown, security and monitoring overheads on corporate devices to cause them to have poor performance. This is especially true when using 3rd-party anti-malware tooling.