Hi Everyone. I am new here and new to Node-Red and Influxdb for that matter. I had some intro programming courses 20 years ago and was never my favorite.
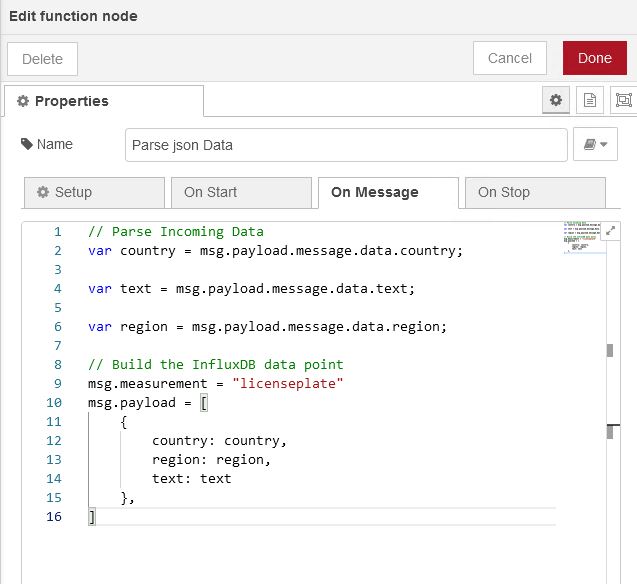
With that being said, I am trying to take license plate data from a camera via MQTT that is coming in as a JSON object and put it into an influxdb so that I can use grafana to run dashboards against the data. Out of all the data in the object, I just want country, region, and text. I want it put into influx so those datapoints are associated with a timestamp. So, for example, at 8/4/2023 16:00 USA, Wisconsin, AFD165. Then, I can pull data to show which plates are there, when they were there, how often, etc.
So far, I have my camera sending the data and using Mosquitto, I am subscribed and I am getting the object in my debug. I also have a working connection to influxdb.
Indeed. It is used to record numeric data over time. Text data is normally only used for filtering, classification, grouping, etc when you want to look at the data.
@thezfunk Is there a particular reason why you chose influxdb?
As others have pointed out, you may find MYSQL or MariaDB a better 'fit' for storing your proposed data, and also present you with fewer problems when you later try to retrieve it.
You guys are asking good questions. I actually am much more comfortable with SQL type databases. I have a MariaDB running on my Synology all the time keeping track of a couple of different things.
This is a side project for work. Without going into the weeds...I was supposed to come up with some dashboards with Grafana. All the developers are swearing that Influx is the way to go for this. I am not familiar with time series databases and I am not convinced this is the case; it was just the one they decided to play with.
I chose to take LPR data, capture it and parse out the important bits like country, state/region, and plate number. Then, I can build dashboards showing frequency of plate numbers, busiest times of day, etc. I am more than happy to start dumping my data into my MariaDB. I have never used Grafana either so that is another hurdle to climb over.
Personally I think I would use a conventional db for that. I suggest asking the developers to explain why they think influxdb would be better. They may be correct.
Grafana works fine with the popular sql databases.
I suspect that is because Grafana has deep ties to InfluxDB (for the old-style queries, not Flux ones). That makes it trivial to create even complex dashboards because it is mostly click-and-select.
But if you are familiar with SQL, you probably don't need that helping hand and as Colin says, it works fine with other DB's too.
Since I already have an SQL database running, I think I will add another node in Node Red that dumps to that. It doesn't hurt to dump to both right now and then see which one will give me more of what I want. Something to do tomorrow between meetings.
Going both ways is the best approach until you are confident about your Influx schema.
Influx seems trivial, but it is different in many ways from conventional SQL DBMS. It requires some experience and knowledge of your data, and more importantly, how you are going to use it. All that is important to find a suitable schema for your measurements. It's often very hard to change that afterwards.
If you keep the raw data somewhere, you can easily reconstruct your Influx data from scratch and it gives some room to experiment with different approaches without losing any data.
At least, that's my approach for those situations that has served me well.