Are you suggesting a command line check before starting node-red for the context read failures?
If using a Pi and SD-Cards, you MUST use a UPS and a well featured power supply otherwise you risk corrupting the whole card. This used to be a major issue. It isn't so bad on newer Pi's but is still a risk. At least have sufficient local power to let the Pi shut down correctly. This isn't a Node-RED issue, it is a Pi hardware issue.
I don't do much with Rpi's but I am certain I saw a UPS 'shield' or similar that fitted a pi and allowed it to finish any writes ans shut down in a controlled manner. It was probably on Tindie and not very expensive. Such a device would help reduce corruption due to random shut downs. The data you are storing seems to have some importance to you, that being the case why not use a better storage medium like at least an SSD?
Sorry for being direct - kindly don't suggest - use UPS, use Server type machines, Linux or Windows on a data center or use RDBMS or use a RAID 5 type disks etc. Unfortunately, we don't have any of these and we have hundreds of installations at the industrial site with extremely fragile (mobile) network or RPi type of hardware. And we can't tell our customers that we don't support without these. Can't change these now. ![]()
Plus this problem happens in a properly UPS-backed up Windows box so the problem is real.
I am not highlighting any inadequacy or gap in node-red and I understand this is not a sunny day use-case for node-red.
Looks like a database (MySQL) or as Colin suggested writing to two files (journaling) would help - I am yet to try it. Any other similar suggestions on top of node-red are welcome!
What happens in the event of a power outage - Does the Windows box attempt a clean shutdown, yet the context store still gets corrupted?
Does the UPS provide power for long enough for the shutdown to complete?
Is the context store device on this Windows box also an SD card, an SSD, hard disk?
Further to @jbudd's questions. You started by saying this happens on power fail on the non-ups devices. Have you confirmed that it is on power fail on those devices, or is that just conjecture?
Also on the Windows machine, is it on power fail that you get the problem?
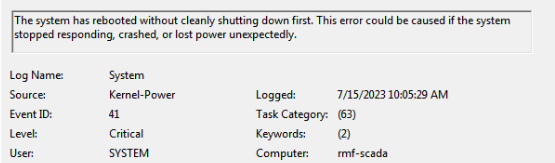
In a particular instance on Windows - Event Viewer says it is rebooted without shutting down first - unexpectedly. This is on UPS and likely have crashed for some reason. It has a regular SATA (Toshiba ATA Disk) drive. I don't know whether it is a power trip or windows crash in this case.
(As said, such a scenario frequents in RPi like device)
The reason why I had mentioned RPi device is that - ideally would like a common solution between Windows, Linux & RPi installations - hence can't start with MySQL as this could be heavier.
This may seem like a crazy idea.. but..
why not use a directory in the file system as a FIFO buffer.
Each data update is wirtten as a (separate) file into this directory. you then have another flow reading these files and sending them on via mqtt. If the mqtt link fails, then the directory slowly fills up. if the pi crashes, then on restarting you either send on the files via mqtt, so you have no data loss, or you may just want to erase them all and start again. by keeping each file to one update, if one becomes corrupt, you still have all the others. Also a smaller file may be less susceptible to becoming corrupt??
Well that looks like a problem internal to the PC, such as a dodgy power supply or motherboard issue. Maybe even corruption of an OS file might cause it. Whatever, the UPS was unable to intervene.
Thinking about your SD card based systems, I wonder if something about your flows or the Node-red context storage processes makes this file especially prone to corruption (possibly the slow stage of writing to flash) or if you are perhaps unknowingly getting other corrupt files too.
Are you certain that the device rebooted after this event?
Can you show us this part of your flow?
Yes, this corresponds to a reboot event in the Event Viewer.
Sure, it is taken from the Guaranteed flow submitted by Colin. Sub flow is used almost as-is.
https://flows.nodered.org/flow/05e6d61f14ef6af763ec4cfd1049ab61
Yeah! this looks like a possible approach I was contemplating as mentioned above.
The problem is to not write the transaction data directly into the context file. I can write it to CSV file (with some minimal buffering - say every 10 seconds or so) and the csv file name and order is mentioned in the context file in the end. i.e context file will have only the filename(s). Minimize the risk of corruption and the context file will remain small and the CSV file is easily recoverable. (I also have the option to write x number of records per CSV.)
One thing that I wanted to bounce off with this team is that - there is always a possibility of truncation of context file every time someone writes into it when something happens to the node-red process (which is likely in any scenario). There has to be a fallback - like continue on error, recover context file upon restart etc. Today the node-red doesn't restart when it cannot load the context file which is a serious issue isn't?
Yes, I think a settings.js option to treat corrupted context as a warning rather than a fatal error might be one possibility.
Does anyone know where the context save code is located? I would like to have a look at it.
My Windows based Node-RED has this exact issue for the past 3+ years.
Node-RED will crash (usually the screenshot Node (the author is not responsive) due to puppeteer doing something it should not) and not restart due to borked context file.
I have about 50+ context files and its a real pain to figure out which one it is due to the long random file names.
Also when it crashes, I am usually in a hurry to get it back up (public facing website) so end up just deleting all the context files and then the site comes up, but all the tables etc are black and the users complain.
But, for a clean stop/start, the context is great.
I use the app 'restart on crash' to monitor Node-RED and restart it 15 seconds after it crashes.
I guess my point is, its not just an issue for a Pi on the edge, but also for a solid Windows 'server class' machine as well. And yes, my PC is on a massive UPS as I cant not have it go down. Its just random Node-RED crashes that cause the issue.
I find this very strange. I would expect the code that saves the context to write it out to a temporary file and only when that was complete would it rename the new file as the current one. If my assumption is correct it is difficult to see how a node-red crash could cause the problem. Are you running reasonably up to date versions of node-red and nodejs?
@jakonnode are you also running reasonably up to date versions of node-red and nodejs in the failing systems?
That could be valuable info.
The PC itself does not restart?
You don't happen to use a similar method to write the context variables as the OP?
For what it's worth here's a little shell script to look for invalid JSON files in the context directory.
Probably it could easily be converted to PowerShell.
#! /bin/bash
NODEREDHOME=~/.node-red
CONTEXTDIR=$NODEREDHOME/context
for f in $(find $CONTEXTDIR -type f -print)
do
if python -mjson.tool $f >/dev/null 2>&1 # Exit code non zero if file is not valid json
then true
else echo $f is bad
fi
done
Found the code. In https://github.com/node-red/node-red/blob/master/packages/node_modules/%40node-red/runtime/lib/nodes/context/localfilesystem.js
async function writeFileAtomic(storagePath, content) {
// To protect against file corruption, write to a tmp file first and then
// rename to the destination file
let finalFile = storagePath + ".json";
let tmpFile = finalFile + "."+Date.now()+".tmp";
await fs.outputFile(tmpFile, content, "utf8");
return fs.rename(tmpFile,finalFile);
}
It is difficult to see how that can end up with a corrupted file in the case of a node-red crash. If the crash happens before the rename then the original file is still there, if it happens after the rename then the new one should be there complete.
The above code was introduced in node-red v1.0 I believe (Use a more atomic process for writing context files · node-red/node-red@10077ae · GitHub)
My PC currently is at 102 days uptime, so no, the PC does not reboot at all.
Just Node-RED restarts. Sometimes it will restart cleanly, sometimes it will not.
Node-RED v3.0.2
nodeJS v18.15.0
I have a lot of 'template' nodes with the option at the bottom 'Reload last value on refresh'. I suspect that a lot of context files are from those nodes.
I also have a lot of flow.set and global.set context commands in my function nodes to pass data around and to ensure arrays are loaded up on a restart etc
If it is node-red-contrib-screenshot - the last update is Nov 24, 2016. Meanwhile the underlying library screenshot-desktop got last (windows related) update 2 weeks ago.
The puppeteer has 286 open issues. (well of course not all of them are really issues but...)
For me those alone will make even
a solid Windows 'server class' machine
kind of irrelevant.
If the running process forced to fail hard, I cant see any reason to expect fully functional recovery from it.
Given the code I posted earlier, can you see how a node-red crash could cause a context file to be corrupted?
@thebaldgeek can you post the section of .node-red/settings.js relevant to context storage please?
[Edit] @thebaldgeek also how often are you seeing the corruption?