I am doing some test runs just to get an understanding of flow execution times and how flows can be optimized in different ways for tighter execution and to give customers a realistic idea of NR "deterministic" abilities. I realize node.js is NOT a runtime built with real time execution or deterministic tasks.
Running tests on quad core armV7 industrial pc.
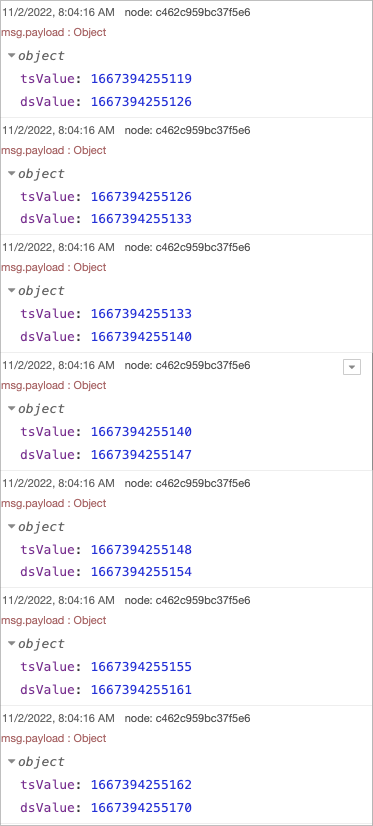
I am running an inject at 0.001 sec interval. I can write to context variables with array.push method in very tight 1 or 2 ms intervals. From the inject node, using a function node to format an object that includes {injected timestamp, current timestamp (Date.now())} then use a second function to get context vars, push the payload {inj ts, cur ts} and push another (Date.now) into 3 context arrays and at most I have a 2 ms between inject timestamps
It is generally very clear between the debug and context arrays that there is about a 1 ms or less time between each.


Where I am quite confused is that adding a write to InfluxDB node, causes many milliseconds to be added not just between the inject to inject times, but also many milliseconds are added between the inject timestamp and the additional datestamps (ds and dn) values captured with the Date.now function at each of the function nodes

My expectation - obviously incorrect, would be extended times between one inject and the next assuming the influxdb is waiting on a response.
or is this expected? are the time intervals likely a result of async callbacks occurring with the influxdb and causing small delays throughout the flow
Did you add the InfluxDB node to the same function output as debug? What happens if you remove the debug link and check the InfluxDB data out-of-band? Does that make a difference?
When you have >1 wire connected to an output, Node-RED forces a COPY of the output msg in order to reduce pass-by-reference issues between downstream flows.
Thanks Julien!,
I removed the double wire output and just looking at the DB as well as the context vars and the times are in-fact several milliseconds tighter on average. I am seeing an average difference from 14 ms between timestamps to an average of 6 ms.
Is there any particular reason that a node msg copy operation seems so expensive? Just curious.
Yes. It has to do an object copy which is a quite expensive operation. You can do some background reading on shallow and deep copies in JavaScript if you are interested.
This all relates to the async nature of node.js processing and the fact that JavaScript objects are passed by reference so when you do something like
const fred = {}
const jim = fred
Fred and Jim are pointers to the same object in memory. So if something later changes fred, jim also changes (well, strictly it doesn't "change" since it is the underlying memory space that changes, fred and jim point to the same space).
The most common "issue" seen in node-red in relation to this is that your debug output is not what you expect because an async process changed the data before the debug node managed to turn the data into a display.
If you want to avoid that but still get 2 outputs, don't forget that you can, for a function node, have as many output ports as you like. That lets you control the outputs.
I have done a little reading on arrays and deep vs shallow operations, I will spend some more time on objects as well. Excellent info - Thanks for the quick reply!