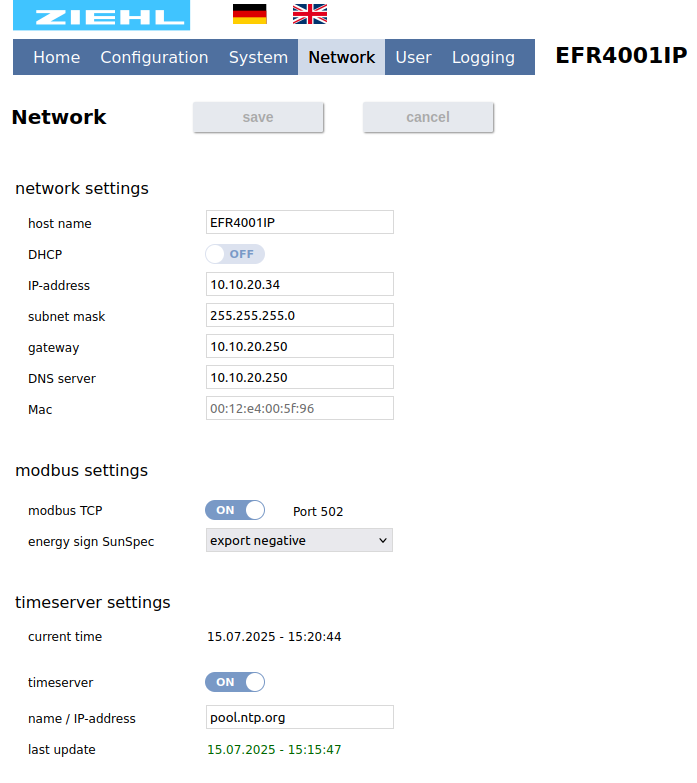
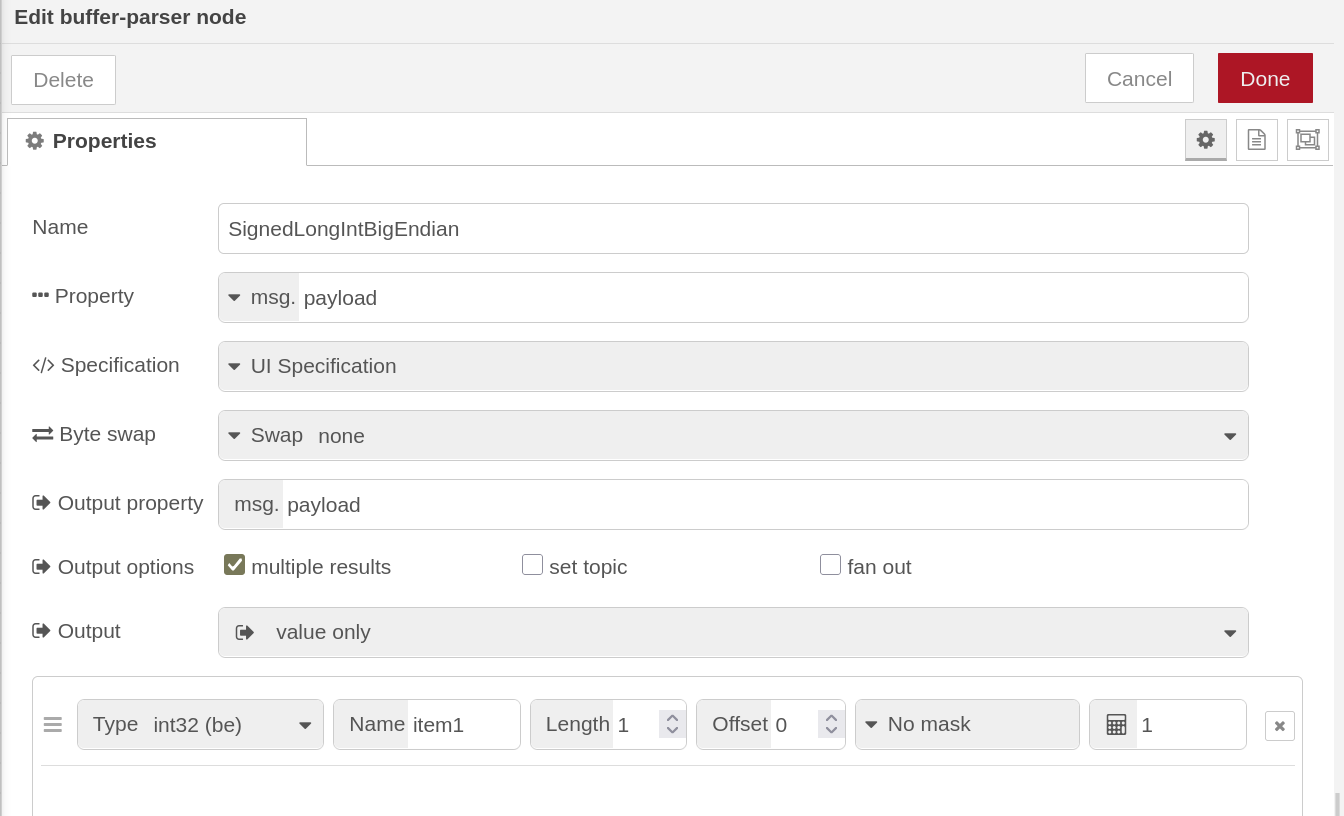
Like to read the apparent power from my Ziehl EFR4001 device for visualisation in my dashboard. The device is in my local network accessible by http where I enable the Modbus TCP setup using Port 502.
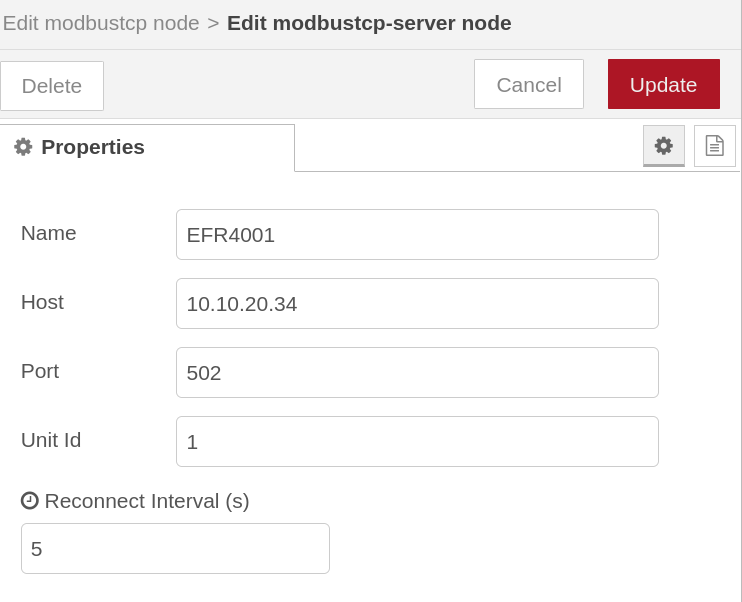
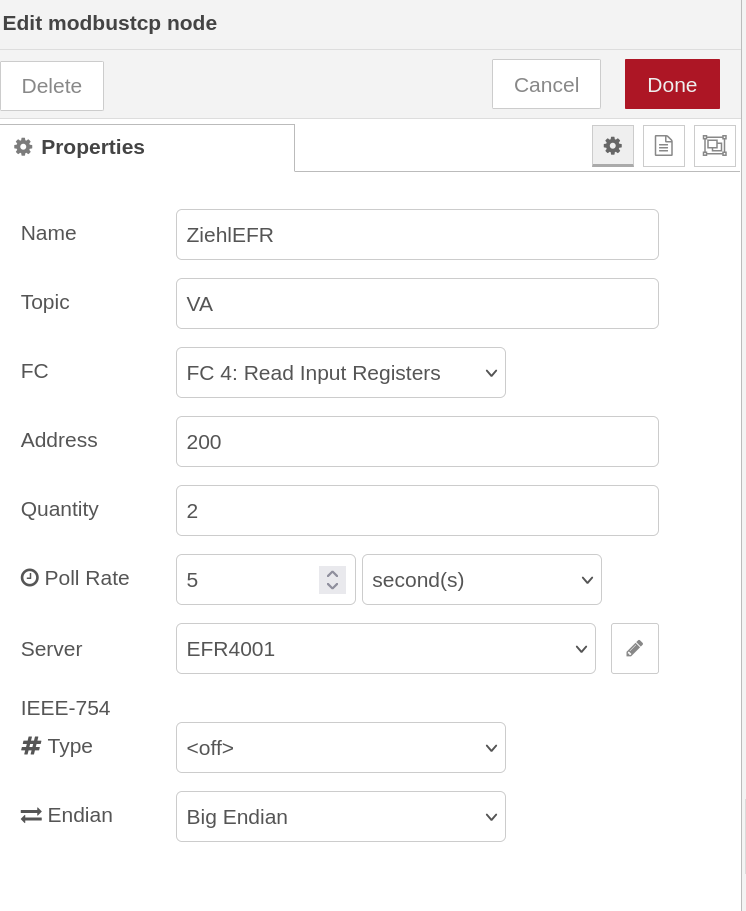
For NodeRed I installed the "node-red-contrib-modbustcp" from what I do not know if this is the correct choice. From there, I used the ModbusTCP client node to read a register using function code FC4.
The client node is setup to connect to TCP Server at adress 10.10.20.34 using port 502 and poll the values every 5 seconds.
Each Modbus TCP register is 16 bit and the signed integer value expected as 32 bit with lowword-highword order. Therefore the number of registers to read seems 2.
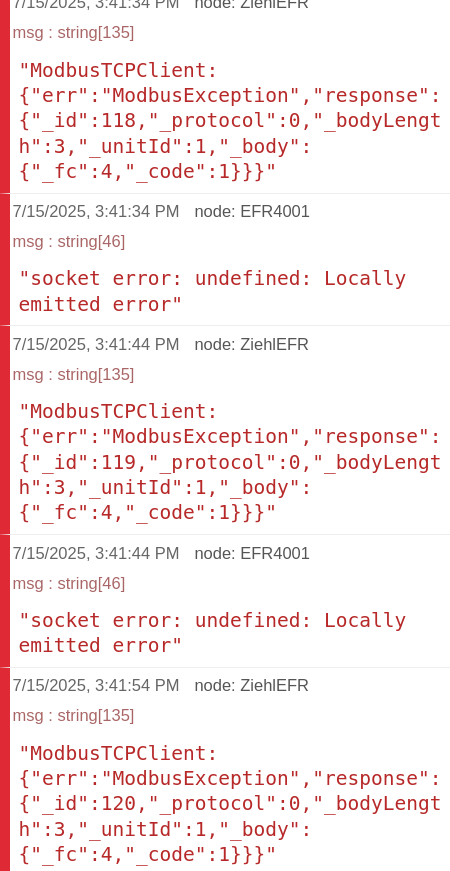
After starting the flow, the node seems to connect successfull but throws error message in console and anything seems generally wrong
After install of node-red-contrib-modbus it seems to work. At least no error message.
One further trick is to use FC3 and not FC4 to read a value. From view of the server, this is a output register while the NodeRed client reads this a a input value.
For contents and values I have to see what format is correct.
Edit: Some values seems correct, other not. Reading only one register works for 16 bit positive values. If value is negative, the complement is needed and for big endian the sign will be lost. Probably I have to follow your advice installing the buffer parser to process signed long integer numbers.
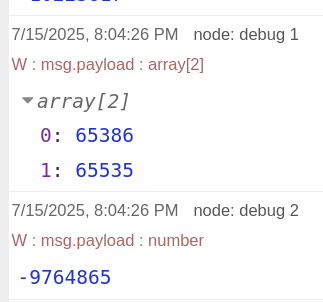
Some results are still wrong. debug1 is before buffer parser, debug2 behind.
Before parser I see array[2] what contains JSON two 16 bit words. Second word are all bits set, what is a negative value. First words complement is 65635 - 65386 what makes about -150 Watt while the buffer parser calculates -9764865. This would be 0x950001 - no sense - where is my mistake?
Some modbus implementations start from 0 others start from 1.
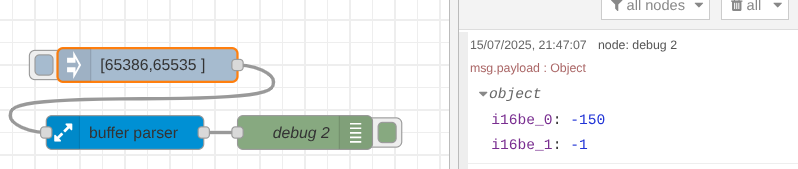
So while you have 2 registers, you may be picking up the last register of the one you want plus the first register of the next value value. Try taking data from 1 register lower than you currently are and it will likely have 65535 (0xffff) in it which should then convert to -150 i32 big Indian.
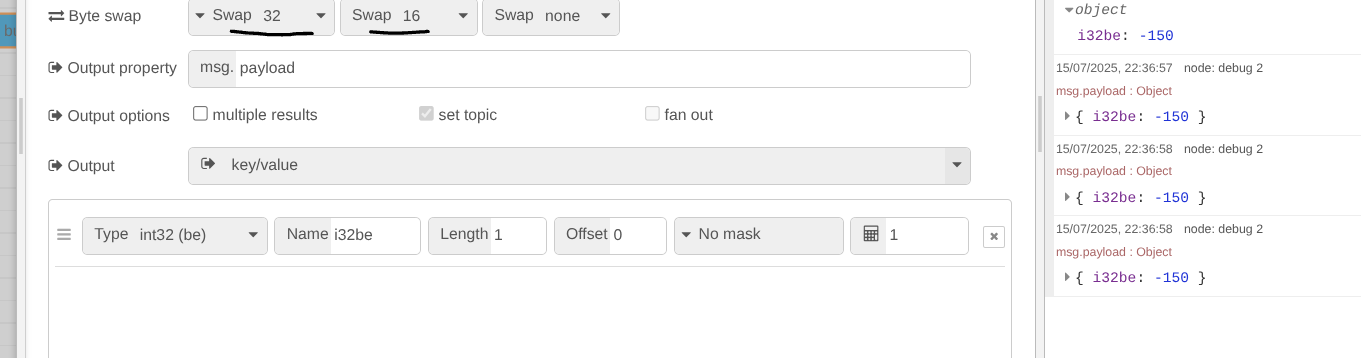
Failing that, the device is doing a 16bit word swap - I have seen this on rare occasions / where the device manufacturer encoded values wrongly. To overcome that you need to do swap32 then swap 16 so that the data words are swapped before the conversion:
NOTE: The swap dont seem to make logical sense but this is the implementation names employed by the NodeJS buffer. If you add an extra row into the buffer parser of type buffer with length -1 and offset 0 you will see what affect the swap options do.
The 32bit signed integers are described there in detail. No word swaps. Bit 0 is at the end of second byte. I wonder about as I always remembered the big endian uses bit 0 located at the end of first word (or byte).
Anyway, your parser reports correct values with register address offset -1 and float big endian. Without the offset no chance for any meaningfull values.
Recognized another detail in the German manual. This describes are 2 diffrent models EFR4000 and the later EFR4001 what is able to provide much more data values. The older EFR4000 model registers maps the range vom 0 to 0xa1 for readings and 0x200 to 0x265 for writing registers. This confirms, the Ziehl implementation starts counting at address 0.
The later model EFR4001 maps its register address range from 0xb0 to 0x186. As my next devices are inverters by SMA and Fronius what also uses the Sunspec registers and your parser converts the IEEE754 correct, I am probably go ahead using Sunspec. This also provides a direct comparison with other manufacturers if Ziehl or node.js is wrong with address countings.
Today, reading of a Fronius Symo was also successful.
I also used the Sunspec IEEE float. In contrary to Ziehl, Fronius also supports Sunspec integer beside IEEE float. This requires to read a second register with a scale factor to calculate the float value in the polling application. IEEE float seems more popular and worked immediately. Thanks to your buffer parser and the -1 offset address what I do not understand up on now. There is explicit warning for the -1 offset mentioned in the Fronius Modbus manual:
I've got a lot of general experience with ModBus, not node-red specifically. ModBus uses 16bit registers but does not require a particular format, it's just bits. The contents could be an integer, big-end or little, it could be 2 bytes of character data, a bit mask, and registers can be combined into a data block that should be interpreted as some other kind of structure. It is not unheard of to store and IEEE float in 2 side by side registers or a really big int value in 4. It is up to the manufacturer and the user to store and recall the data. Most of my ModBus work is in RB/Xojo and PHP using memory blocks to request and read data. While I've never done it myself in JS, you should be able to use auint8Array and DataView objects to read registers into a buffer and then interpret that buffer as whatever data format you need, be it a null terminated string, float32/64, integer, or somethig really complex.
The parser of @Steve-Mcl works fine for me but another general question arrised as my installation suffered by spurious osciallations using wrong values for regulation, even sometimes NaN from where I cannot explain where it comes.
Some Modbus devices are solar inverters. They disappear from ModbusTCP after sunset for the reason of no power supply. Probably I can change this behavoiur in the setup but possibly this might lead to some intermediate wrong values.
Node Red is a single instance what runs on any target. The dashboard might be opened at more than one http browser. All dashboard show same values. If one user changes any switch or input value, the other instances reflect this changes.
Reading from a Modbus HW device should be no problem for more than one instance. Writing should always be limited to only one instance. This is done by running NodeRed only at one hardware not starting the flow unintentionally twice. Writing highword, lowword sequences should be locked inside the device using any semaphores.
Probably there is not too much what I can do wrong using Node Red and I have to observe the reliability of the installation some more days.