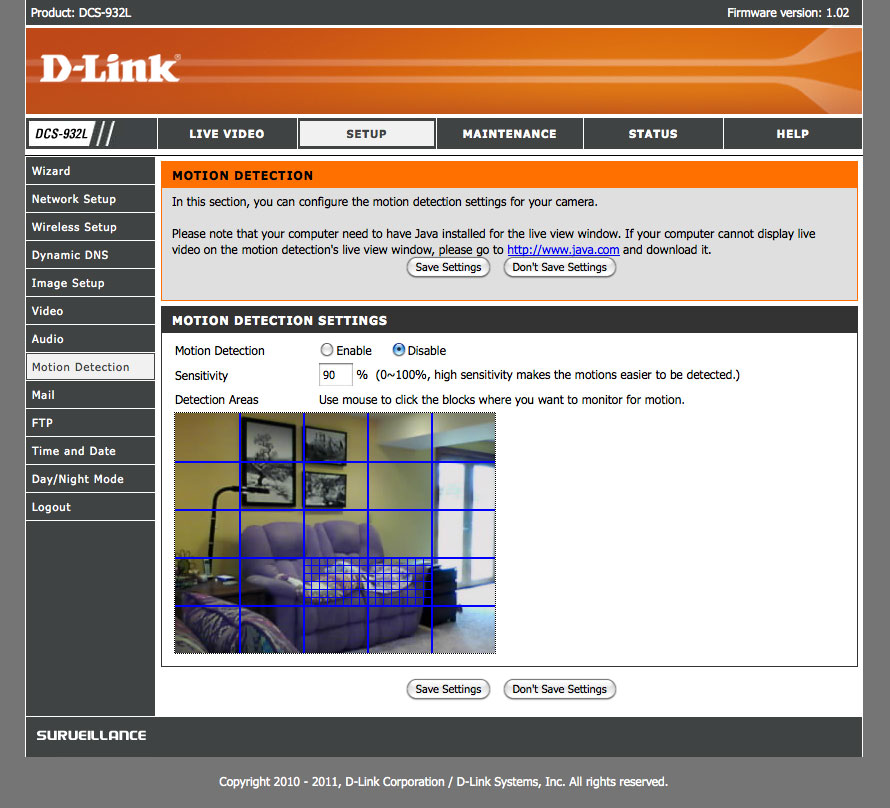
I have currently installed some pieces of relative cheap IP camera's, that I use as a motion detector. These camera's has become end of life. For what I paid for it (10 Euro each), they have a lot of possibilities, such as motion detection, but also a number of disadvantages.
To use it as a motion detector, you can set up a grid pattern and if motions has been detected inside the grid you can generate an alarm.
This application runs in a FreeBSD (TrueNAS) jail, controlled by PM2.
If I receive in Node RED an incoming MQTT message, I analyze the snapshot by means of tensorflow. As soon a person is detected in this snapshot an alarm and also other controls, such as switching on the lights, generating a voice alarm and sending an email (with picture), are initiated.
This is all Node-RED "logic" and works fine and reliable for more than a year.
The only thing is that I want to get rid of that configuration in the IP camera and I prefer to receive the image directly into Node-RED, without the intermediate step of the FTP and the conversion to MQTT. I can receive the image stream directly by Node-RED.
Does someone know a method to define a similar grid (preferably somewhat more accurate).
I cannot find a node who can do that or I make a mistake.
Something, such as defining a "region΅ in the "worldmap΅ node would be fine.
I read the README at your Github page and watched the demo.
It looks exactly what I might need and even more. I would have been happy with a rectangular shape and you offered a polygon.
The remaining 5%, how essential is this? I mean is the node already usable?
What has to be done to complete this development? Testing? Writing documentation?
It looks to me quite functional.
I think I can install it directly from your repo or is that something you do not recommend?
Well to be honest I don't have a clue anymore where I left the developments.
I think most of it worked, but you will need to test it to find out...
You can install it directly from my Github repository via following command (from within your .node-red folder):
I am not very sure about that. I cannot offer a full working solution yet:
This node allows you to draw a polygon on top of an image manually.
For every messge that passes through, that polygon will be added to the message (as an array of points).
This node does NOT draw the polygons on your images. I have been experimenting to do that in pure javascript, but it was dramatic for performance. I also tried to do it in Webassembly but didn't find a true working solution yet.
Moreover other nodes are required for a full working solution:
You might want to calculate intersections between these zones and e.g. bounding boxes of detected objects. I have been developing such a node, but it is also not ready yet. I now see that I haven't even put it on Github yet...
You might want to transform polygons and bounding boxes, in order to be able to calculate these intersections. I have build the node-red-contrib-polygon-transform to do that, but again I don't know anymore where I left the development of that node...
So at the moment your camera is only sending 1 frame when it detects motion. So tensorflow doesn't have much work to do.
If you remove that step you will have many frames per second, so much more work to then detect objects in real time.
You don't say what you run node red on, but it may not cope well with this load.
So you really need to have the motion detection part, to then trigger object detection.
I don't know about your camera but often you can request a snapshot via an API, If you had a PIR or similar this could trigger NR to grab a frame and then pass to tensorflow.
For sure, sending a "live stream" will cause a huge load in comparison to just send single frames when movement is detected. To be able to run real time video analytics on video streams (like 25 frames per second) you will need a very powerful computer with a NVIDIA graphic card so you can utilize GPU:s
You should otherwise, if you do not have such equipment, not send frames to NR "without reason", i.e. only ask for analyze when detected movement has happened
It is of course inconvinient to have to configure each camera as you say. In my case I'm using Motion software as a "middle-ware" between my cameras and NR. So I configure the active areas and other params in Motion, in this way avoiding to overload NR and only analyzing when really needed. I assume another alternative , also with better GUI, would be to use MotionEye
For analyzing in NR, tensorflow nodes are okay but for higher accuracy you should use YOLO. I do that but I run the analyzer in a NVIDIA Jetson Nano to get quicker analyzes, well below 0.5 second. I also made some tests lately using a RPi4 w 64 bit OS and the YOLO algorithm required some 4 seconds or so to analyze a single frame, this might be acceptable, depending on your requirements
Agree, that is correct. Node RED receives a snapshot (jpg), when motion is detected and then only when the system has been armed.
If I decide to analyze a "live" video stream, it will be far to much for my hardware to handle the object detection by tensorflow. However if it is only a jpg image, it is still possible, but the critical point is to have the right trigger.
Currently it is handled by the motion detection in the camera itself.
The Node RED instance runs in a TrueNAS (= FreeBSD) jail (virtual machine) and it takes between 5-10 seconds to analyze the object. For my goal it is acceptable, but it will not work for a "live" stream.
Agree. I use currently the camera's possibilities and have decided to keep it that way
I can send a snapshot in case of motion and that works fine.
Unfortunately I do not have that powerful hardware available yet.
It is not a problem for the standard configuration. With the Chrome browser and the add-on UA spoofer, I'm able to emulate another User Agent and as Internet Explorer I can configure the standard camera settings. This is not something you do every day, and as it has been done, it is not a real problem. However in order to configure the active grid (sensitive area), you need to have java installed. So that is not so easy to change.
I used both ZoneMinder and MotionEyeOS before. I did replace these, as I hardly looked to the interface, by the IPCam2MQTT solution, I currently use.
Also noted that Calin Crisan has stopped his contribution to that project for personal reasons.
It has been transferred to the new motioneye-project GitHub organization with a new developer team. Let's see how that evolves.
Probably YOLO is more accurate, but up to now TensorFlow is doing the job.
I'm more in need of a better way (higher accuracy) to configure the grid, which is not very detailed. See the picture in my first post.
@BartButenaers new node looks more detailed, but as Bart already indicated, this node is not really ready and I do not expect that in case of any issue with this node Bart can offer support, as he seems to be very busy.
It would be possible to receive the jpg (with an unconfigured grid in the camera), analyze by means of TensorFlow and compare the bounding box with the configured area in Bart's node.
But for above mentioned reasons, I keep my current solutionwhich works fine for approx a year.