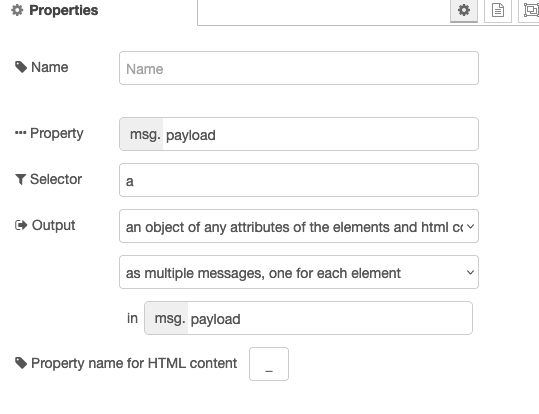
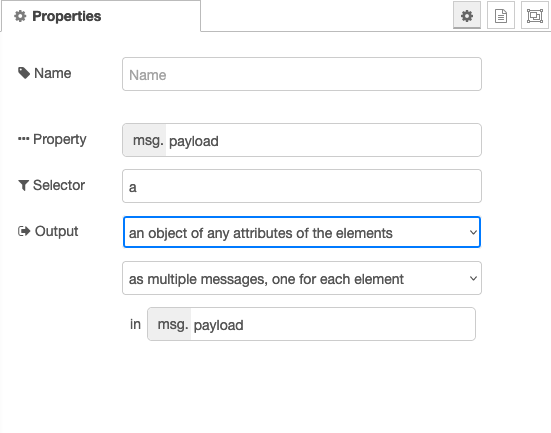
What if you use the Html node twice ?
Once to get the attributes and one for the content and
then use a Join node to merge the results in one msg
Test Flow :
[{"id":"3bb37f38619ad9e9","type":"inject","z":"54efb553244c241f","name":"html","props":[{"p":"payload"},{"p":"topic","vt":"str"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","payload":"<a href=\"url\" target=\"_blank\"><b>some text</b></a>","payloadType":"str","x":270,"y":3180,"wires":[["b332d974fcb36acd","71c95918952af649"]]},{"id":"b332d974fcb36acd","type":"html","z":"54efb553244c241f","name":"attributes","property":"payload","outproperty":"payload","tag":"a","ret":"attr","as":"multi","x":460,"y":3140,"wires":[["5d8eb3e4bf5506ae"]]},{"id":"6cd4a1f22a03b652","type":"debug","z":"54efb553244c241f","name":"debug 59","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":860,"y":3180,"wires":[]},{"id":"71c95918952af649","type":"html","z":"54efb553244c241f","name":"content","property":"payload","outproperty":"payload","tag":"a","ret":"html","as":"multi","x":460,"y":3220,"wires":[["3a885d7c3413c462"]]},{"id":"b1508985cc7d5986","type":"join","z":"54efb553244c241f","name":"","mode":"custom","build":"object","property":"payload","propertyType":"msg","key":"topic","joiner":"\\n","joinerType":"str","accumulate":false,"timeout":"","count":"2","reduceRight":false,"reduceExp":"","reduceInit":"","reduceInitType":"","reduceFixup":"","x":690,"y":3180,"wires":[["6cd4a1f22a03b652"]]},{"id":"5d8eb3e4bf5506ae","type":"change","z":"54efb553244c241f","name":"","rules":[{"t":"set","p":"topic","pt":"msg","to":"attributes","tot":"str"}],"action":"","property":"","from":"","to":"","reg":false,"x":555,"y":3140,"wires":[["b1508985cc7d5986"]],"l":false},{"id":"3a885d7c3413c462","type":"change","z":"54efb553244c241f","name":"","rules":[{"t":"set","p":"topic","pt":"msg","to":"content","tot":"str"}],"action":"","property":"","from":"","to":"","reg":false,"x":555,"y":3220,"wires":[["b1508985cc7d5986"]],"l":false}]
Result :