I'm interested in getting some community feedback on the subject of testing your flows.
More specifically, have you created a set of tests you can routinely run against your flows to verify they are working?
Have you created a test suite outside of Node-RED (eg using mocha or some other test runner) that you can run against your flows?
Have you create tests within Node-RED itself that you can run, and if so, how?
I think this is a really rich topic to explore and one we've touched on before. There are early thoughts around how we could better integrate testing into the Node-RED editor. But for now, I'm interested to hear about what you're doing today.
No, I just use the technique of testing a new bit of flow using inject and debug nodes to check the functionality of that section and assuming that changes I make don't mess up other areas, or at least that any effects will be fairly obvious. Occasionally I am bitten by that of course. In my environment (home automation with no safety critical stuff) I consider that acceptable. In other environments that would not be acceptable of course.
I usually use try-catch with 2 node.status directly in the try (an msg entry and if it reaches an output) and a red node status in the catch with node.error to capture any errors.
With node.status it is easy to see where the fault is located
Examples:
I also use nssm to create a Node-Red service, since it allows me to have a list of logs
Same as Colin here, similar environment - home automation.
Build my flows bit by bit using the node.status and debug nodes before consolidating them into single sensible nodes, often testing in a separate flow so that it doesn't affect anything connected to the system until tested.
One request - I'm keen to hear about the positive examples of people doing the things I've described, rather than lots of "I don't do that" type replies
I'm similar to Colin. Though I also try to keep segments of flows independent of each other in order to minimise the impact of later changes. With the home automation flows, I may go months without making any changes so it is unlikely that I would remember complex interactions.
For testing custom nodes, I'd love to do some proper testing but finding time to do the coding is hard enough. Not being a pro developer, I don't have the skills (nor the time to learn them) for setting up & running test harnesses and developing tests as well as code. I'd also love to use the test node but again, the complexity means I probably will never get time until I retire! (A few years yet).
Sorry, your reply crossed over this post. The positive(ish) takeaway is the currently, testing is too complex for many Node-RED users I think?
So far I’m just utilising the same techniques I’d use professionally: run it through with sample inputs for all situations. Different testing strategies work for that, but Modified Condition/Decision Coverage stays a favourite for the switch nodes. A pairwise data combination test if the situation really asks for it. Although the Elementary Comparison test is actually perfect for flows, especially in an MC/DC combination I haven’t used it yet. The Sogeti techniques I got taught for it have an issue that result in an incomplete coverage and so far I haven’t seen an improved approach for it (I demonstrated the issue to Sogeti’s examinator, haven’t heard about it since).
Context: I’m a test engineer by trade, taught through Sogeti’s TMap Next approach, but specialised in automating black box environments for integration and acceptance tests, usually with a written out test suite based on a combination of DCT with MC/DC to come to each test case.
Because of those environments the most important lesson is to never trust user input, especially not when it can be customised. In practice that means my flows can get pretty complex for the added testing of input before I run it through the regular clauses. I have written (partial) test suites for my code, although not through any of the usual suspects. My test suites exist on paper, with step by step test cases to execute on my flows where I specify the input or situations to test, and the outcome they should have. I am thinking of using a JavaScript based testing environment for it in the future, but frankly I wouldn’t have a clue how to set that up combined with Node-RED. I already find that hard enough to set up with custom nodes I’m working on, especially when compared to working with JUnit in Java, or the different unit testing frameworks I’ve used in Python.
A simple thing I do that has not been mentioned is to insert lots of node.warn statements into function nodes. These not only display the values of variables (including context) that I want to track, they can be made conditional on the execution reaching certain points or variables having certain values. I sometimes insert function nodes into a flow only for this purpose and remove them when done debugging.
I hope that @knolleary will follow up by asking if there are features that could added to NR to improve testing/debugging. I have some suggestions, but they might not be in order here.
At some point we will, but that is not the purpose of this thread. We want to capture what people are doing today so we can try to document today's best practice.
Same as Colin (sorry Nick). NR is good at communicating with IoT stuff. Developing testing scenarios would involve taking into account communication problems, time outs, different messages sent from different sources at different times, etc. This is easily done with manually activated inject nodes. Using a testing suite would mean learn how the suite works and I don't have time to spend on this for now. The usual logic of the flows (switch/change/etc nodes) doesn't require a complex testing suite IMHO. The function nodes might involve more complex logic so maybe there's a need there ...
I always try to think what if... the output from a sensor sends an error code instead of a data reading. What if the response to a http request results is no response or malformed formatting. etc, etc.
...then how would my flow cope? can it handle the abnormality or would it cause bigger issues?
To try and head these off, I add an inject node and inject abnormal values/formats into the flow, to see how the flow responds (using node.warn's & debug nodes), then I look at what strategy to put in place to handle it.
Of course this is pretty basic stuff, and deals with known knowns, but not much use with unknown unknowns!
I try to test my flows by running them in a "simulation mode", i.e. injecting same type of data as it later will receive live. For specific needs, specifically for flows built for "long term" data collection, I have also configured the logic as a simulator allowing me to test the logic with data injections at higher rate to check if the logic gives the expected result
Apart from this I'm continuously testing that "everything in my system is working as expected". But maybe this is more a topic of Monitoring?
Anyway, this is how I thought when I built & configured my system;
Node-RED is the master of my relatively complex & distributed system, today comprising 7 RPi's, 1 Jetson Nano and 1 Lenovo laptop. In addition to Node-RED, I have a number of external services and applications running in all of them. Communication between all is mainly utilizing MQTT
My "Main" Node-RED instance is monitoring the others as well as all the various services (mostly written in Python) and applications; means some commands are sent out regularly and a certain qualified response back is expected (kind of heartbeat). If the "heartbeat" stops, a restart of the service or app is first initiated. If this should fail, the targeted device will keep rebooting until the service is back and operational. If "anything" should go wrong with Node-RED itself, I trust systemd to handle the restart. To notify myself that something is not functional, I use Telegram to provide me with details of the failed service or application. When "everything" is up running again, I get a final "All systems go" notification. This setup has worked very well, things has sometimes stopped working but they have always recovered correctly. So far, so good.
Why so many devices? Well, mainly it is about distance and location; my distributed video system setup has 4 wifi connected RPi's with 2 USB cameras in each. I could throw them all out and buy new wifi ip cameras, but hey, they are all working pretty well as they are. Then I run the video analytics in the Jetson Nano, the laptop handles the video storage. Some of the other RPi's are justified simply because it is easier to use wifi instead of installing new wires. Thats about it.
I have a need for a flow. There is expected input and output. I setup my flows to filter for the expected input only and block anything else that might come in, I see this as a catch-all without looking at it (although initially most input-data is known). If something fails later on investigation starts and enhancements are applied where needed.
Then again, I try to keep my flows very simple and concise, I see node-red as a mediator/translator between source and destination, like glue. If I need more than 20 nodes (for the mediation), I failed and will reiterate to streamline it. This, to me, is the beauty of node-red, certain things can be done in such a simple way that our brains are not even used to it and tend to overengineer. The simplicity can eliminate potential problems down the road as well.
I can imagine that on industrial scale the requirements/implementations are completely different, I hope you get a response from those.
Test is something little bit different then debug, so it can be more complex. Test NR itself is different that test all system.
For NR I do more or less what other persons already told, inject and debug nodes, usually I add a log file in txt where I can check what happened in a second time.
For test of the system I usually add trap to catch not regular events. i.g. if I expect to receive a message every 10 minutes i put aside of the flow a timer node that send message if not reset after 15 min (or 18, 20, 25...)
The anemometer send me the number of turns done every 15 sec. but it send also a sequential number in order to be sure no message has been lost.
personally I think it's much more complex to test the whole system that NR itself.
I have used the power of node red for improving test automation at some of my customers. And now we are trying to implement node red as an Low Code RPA solution and we have build some automated tests where the node red deployment is a black box. The test cases are written for interaction with interfaces that we have build with node red. So far I have already had succes testing rest, mq, mqtt and just plain html sites that we have build with node red.
For tooling I used robot framework.
On my to do list is still to build a good DTAP environment and CI/CD approach for my node red applications.
It has bee said quite a lot already. Just some additions:
I run simulations in parallel to increase system load.
I do two types of simulations (in NR): logic based and "invalid value" based.
I have also implemented (a very trivial) "Crash"-Node which crashes the NR-instance. To my flows it is very important that everything reconnects properly after restart, connection timeouts, connection losses...
When I'm testing my solutions based on Node-RED, I'm considering two parts:
The Node-RED flow is the easy part.
I'm using injection and debug nodes to perform tests and check results, as commented before in this thread.
However, the harder part is the integration of the Node-RED flow with upstream and downstream systems.
Node-RED excels in heterogeneous hardware and software, and most of my projects interface with an upstream data provider and a downstream operator.
The real challenge is to ensure all upstream events are taken into account (e.g. MQTT messages), once and with no loss. Same for downstream systems (e.g. mySQL database), with no overflow.
I have not yet found a satisfactory solution or protocol to ensure integration is robust and reliable. Most of the time, each sub-system works fine (upstream, Node-RED flow, downstream), but integration faces scalability issues, mostly high jitter.
With respect to unit testing (or sort of unit testing).
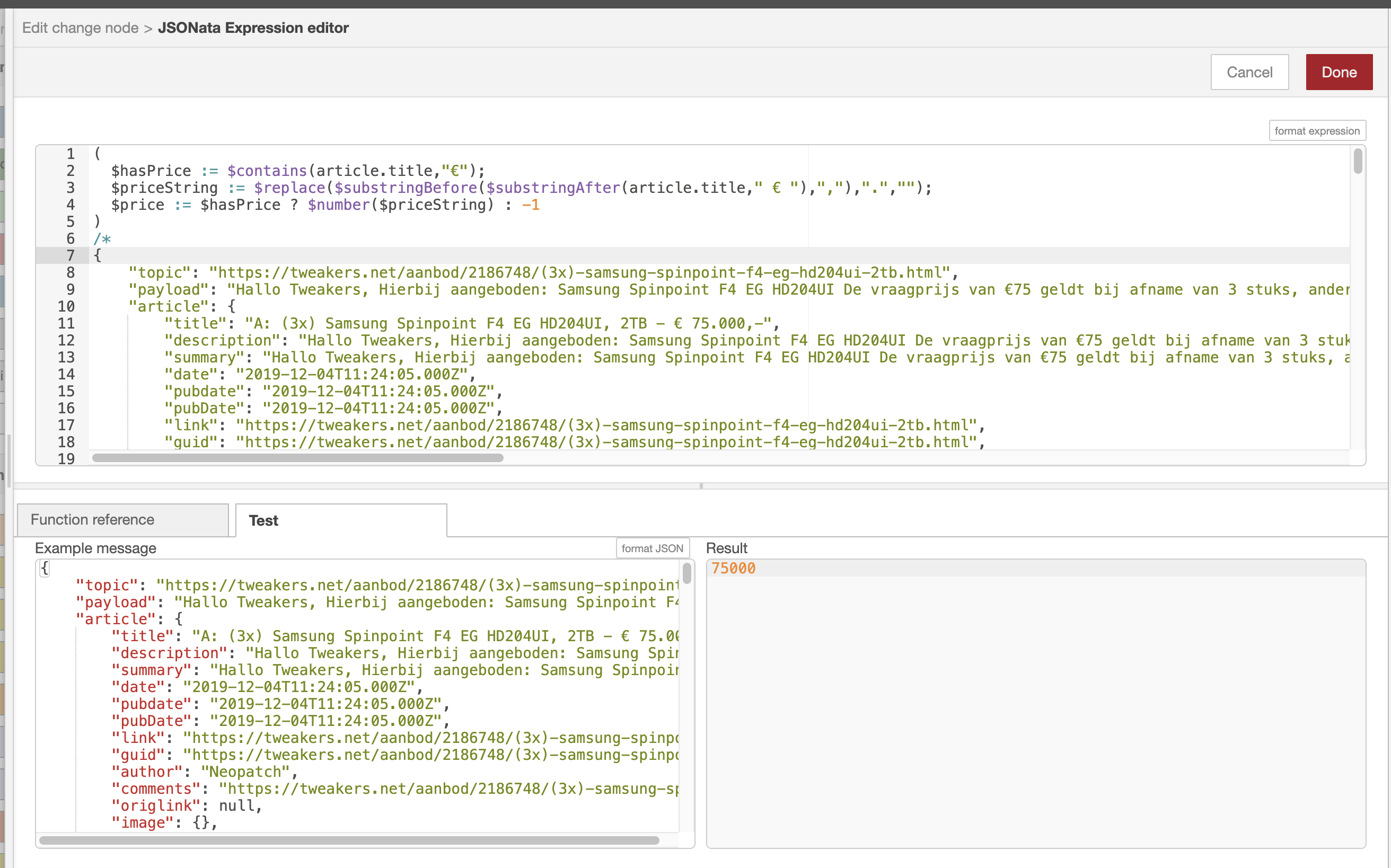
Instead of function nodes, I try to use JSONata in change nodes.
The advantage of this is that you can immediately test your JSONata based on the actual input message which you can copy pasted from the debug bar. Moreover you can very easy edit the input message and see how this impacts the result.
Another tip related to this. The contents of your actual test message entered in section Example message (see screenshot) are not stored, so you need to manually reenter it when you want to retest it later again. To assure that the test message is not lost, I am also copy pasting it in a JSONata comment I have created just below the actual json expression (see example below). This allows me to quickly retest it again by copy pasting test message from the JSONata comment.
Have use mocha and node-red-node-test-helper but annoying to set up especially if many nodes in flow to test.
I wrote a node that sends out a message and and looks for message coming back in input that matches expected results. quick to set up and build a set of test and visually easy to see results. Plus works within node-red rather than external.